▋前言
除了逐字稿與講者標註,另一個重要維度是「學生情緒」。在課堂中,老師能從表情、動作感受到學生反應;在只有語音的情況下則需要 AI 來幫忙做語音情緒辨識 (Speech Emotion Recognition, SER)。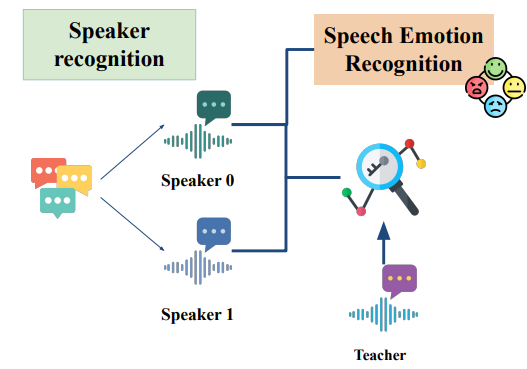
▋內容
我們的設計思路是
特徵提取:使用 Wav2Vec 從原始音訊 waveform 學習上下文特徵。
情緒分類:在 SpeechBrain 中搭建分類器,將輸入音訊標記為 快樂、悲傷、生氣、中性 等情緒。
片段分析:為了避免整段平均導致情緒訊號被沖淡,我們選擇 逐片段分析,並繪製時間序列曲線。
挑戰與限制
情緒標註本質上主觀,不同標註者可能給不同標籤。
相同的文字,不同語調會導致完全不同的情緒判斷。
即便如此,SER 仍然能提供有價值的參考。例如:課堂前 10 分鐘專注度高,後段開始出現困惑與分心,幫助老師回顧教學節奏。
▋下回預告
下一篇將整合四大模組,介紹我們的 系統架構與資料管線(data pipeline)。
▋參考資料
SpeechBrain
Emotion Recognition from Speech Using Wav2vec 2.0 Embeddings
圖片源自競賽成果簡報


 iThome鐵人賽
iThome鐵人賽